

📉 Gérer la relation client à l’ère du tout-numérique est devenu un véritable parcours du combattant pour les entreprises. Aujourd’hui, les consommateurs n’ont plus la patience d’attendre : ils exigent des réponses instantanées, précises et ultra-personnalisées, de jour comme de nuit.
🌪️ Face à ce niveau d’exigence inédit, les solutions d’assistance traditionnelles prennent l’eau. Les chatbots de première génération, engoncés dans leurs scénarios rigides, tournent en boucle dès qu’une requête sort de leur script. Résultat ? Une frustration client qui explose, des tickets de support qui s’accumulent et, in fine, des millions d’euros de chiffre d’affaires perdus pour cause d’expérience utilisateur défaillante.
💡 C’est précisément pour transformer cette friction en opportunité que Salesforce vient de frapper un grand coup sur le marché de la tech. Le leader mondial du CRM a officiellement annoncé le rachat d’une pépite française de l’IA conversationnelle pour la somme vertigineuse de 800 millions d’euros. Chez Usine-Chic, nous avons décortiqué cette opération majeure qui promet de révolutionner l’interaction client-machine.
Une acquisition record pour consolider l’empire du CRM
Dans la course effrénée à l’intelligence artificielle générative, Salesforce ne compte pas laisser la place aux doutes. En déboursant 800 millions d’euros pour s’offrir cette jeune pousse tricolore, le géant de San Francisco réalise l’une de ses plus grosses opérations de croissance externe en Europe depuis l’intégration de MuleSoft et Tableau.
Cette startup parisienne, qui s’était jusqu’ici illustrée par sa croissance fulgurante (bootstrap et levées de fonds successives menées par de grands VCs européens), n’est pas un simple gadget technologique. Elle a réussi le tour de force de développer des agents conversationnels capables de comprendre l’intention complexe d’un utilisateur, ses nuances émotionnelles, et même l’ironie, le tout en temps réel.
« L’intégration de cette technologie d’avant-garde à notre écosystème Agentforce va nous permettre de combler le fossé entre l’automatisation brute et la véritable conversation humaine. C’est une fierté de voir que l’excellence de l’ingénierie française vient nourrir notre vision globale. »
— Marc Benioff, PDG de Salesforce, lors de l’annonce officielle
La technologie au cœur de ce rachat : au-delà du simple chatbot
Pourquoi un tel montant ? La réponse réside dans le fameux « gain d’information » que cette solution apporte. Contrairement aux surcouches basiques construites à la hâte sur des API publiques d’OpenAI ou d’Anthropic, la pépite française a développé une architecture propriétaire pensée dès le premier jour pour les environnements B2B exigeants.
Voici les trois piliers qui ont séduit Salesforce :
- 🧠 L’approche « multi-intentions » : Le modèle est capable de traiter des requêtes imbriquées (ex: « Je veux annuler ma commande d’hier, mais conserver mon abonnement premium en changeant ma carte bleue ») sans perdre le fil.
- 🛡️ Souveraineté et conformité européenne (RGPD) : Les données clients ne sont pas utilisées pour réentraîner des modèles publics. Le traitement localisé en Europe garantit une sécurité hermétique, un argument de poids pour les secteurs bancaires et assurantiels.
- 🔌 L’intégration native : L’outil ne se contente pas de discuter, il exécute. Il est conçu pour s’interfacer directement avec les bases de données d’inventaire, de facturation et de logistique.
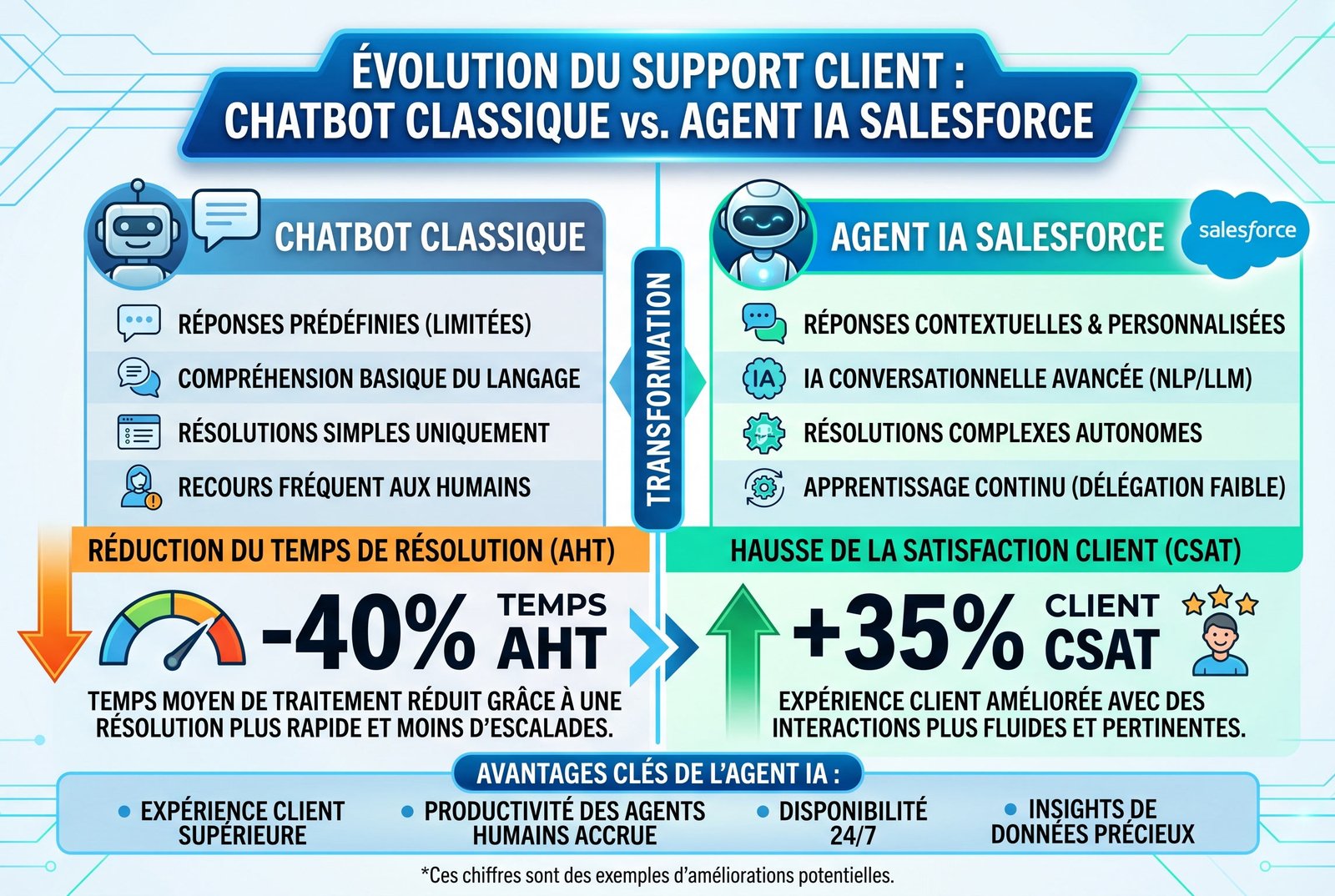
Ce que cela change pour les utilisateurs de l’écosystème
Pour les entreprises qui utilisent déjà les clouds de Salesforce (Service Cloud, Sales Cloud, ou Commerce Cloud), cette annonce est synonyme d’une mise à jour technologique massive prévue pour les prochains trimestres. Nous pouvons anticiper un déploiement fluide où l’IA française deviendra le copilote omnicanal par défaut de la plateforme.
Concrètement, les équipes du service client vont pouvoir se libérer des tâches de tier 1 (mot de passe oublié, suivi de colis, FAQ basique) pour se concentrer sur l’empathie, la vente additionnelle et la résolution de litiges complexes. Un gain de productivité estimé à plus de 30% par les analystes du secteur.
La French Tech, vivier mondial de l’intelligence artificielle
Cette transaction retentissante confirme une tendance lourde : la France s’impose comme la vallée mondiale de l’IA. Après les levées de fonds astronomiques de Mistral AI ou de H (ex-Holistic), c’est au tour des startups orientées vers l’application métier (SaaS) de prouver leur valorisation sur la scène internationale.
C’est un signal fort envoyé aux ingénieurs français et aux investisseurs. L’écosystème hexagonal sait non seulement créer des modèles de langage fondamentaux, mais il excelle également dans la création d’expériences conversationnelles capables de séduire les géants de la Silicon Valley.
Foire aux questions (FAQ) sur le rachat
Quand cette nouvelle technologie sera-t-elle disponible dans Salesforce ?
Bien que le calendrier précis n’ait pas été entièrement dévoilé, les premières briques de cette IA conversationnelle devraient être intégrées aux modules Service Cloud et Agentforce d’ici la fin de l’année, d’abord en version bêta pour les clients Enterprise.
L’équipe française va-t-elle déménager aux États-Unis ?
Non, Salesforce a confirmé sa volonté de conserver et de développer le centre de R&D à Paris. L’objectif est de s’appuyer sur le bassin de talents locaux en ingénierie et en machine learning, et de recruter plusieurs dizaines de chercheurs d’ici l’année prochaine.
Quel est l’impact de ce rachat sur la protection des données des clients européens ?
L’opération devrait au contraire renforcer cette protection. Le respect strict du RGPD était inscrit dans l’ADN de la startup française. Salesforce prévoit d’utiliser cette expertise de conformité by design pour rassurer ses grands comptes européens face aux craintes liées au Cloud Act américain.